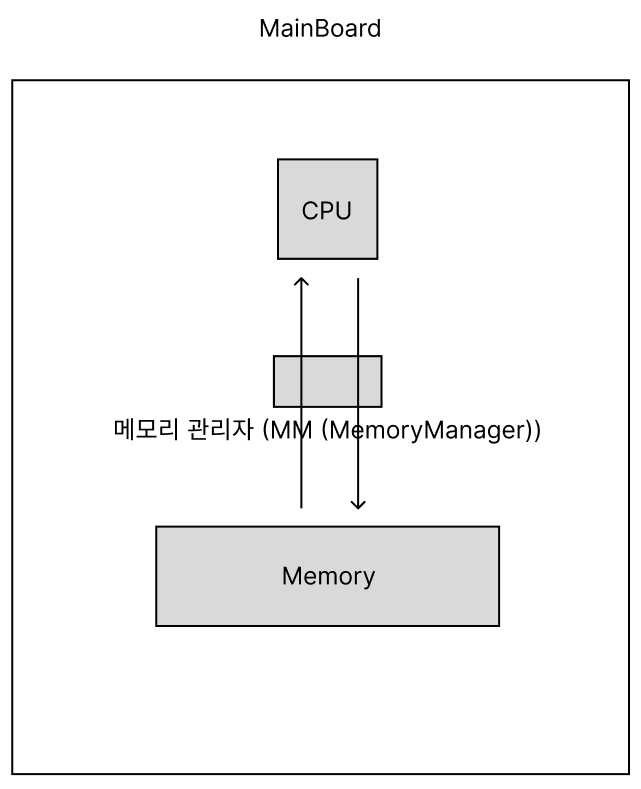
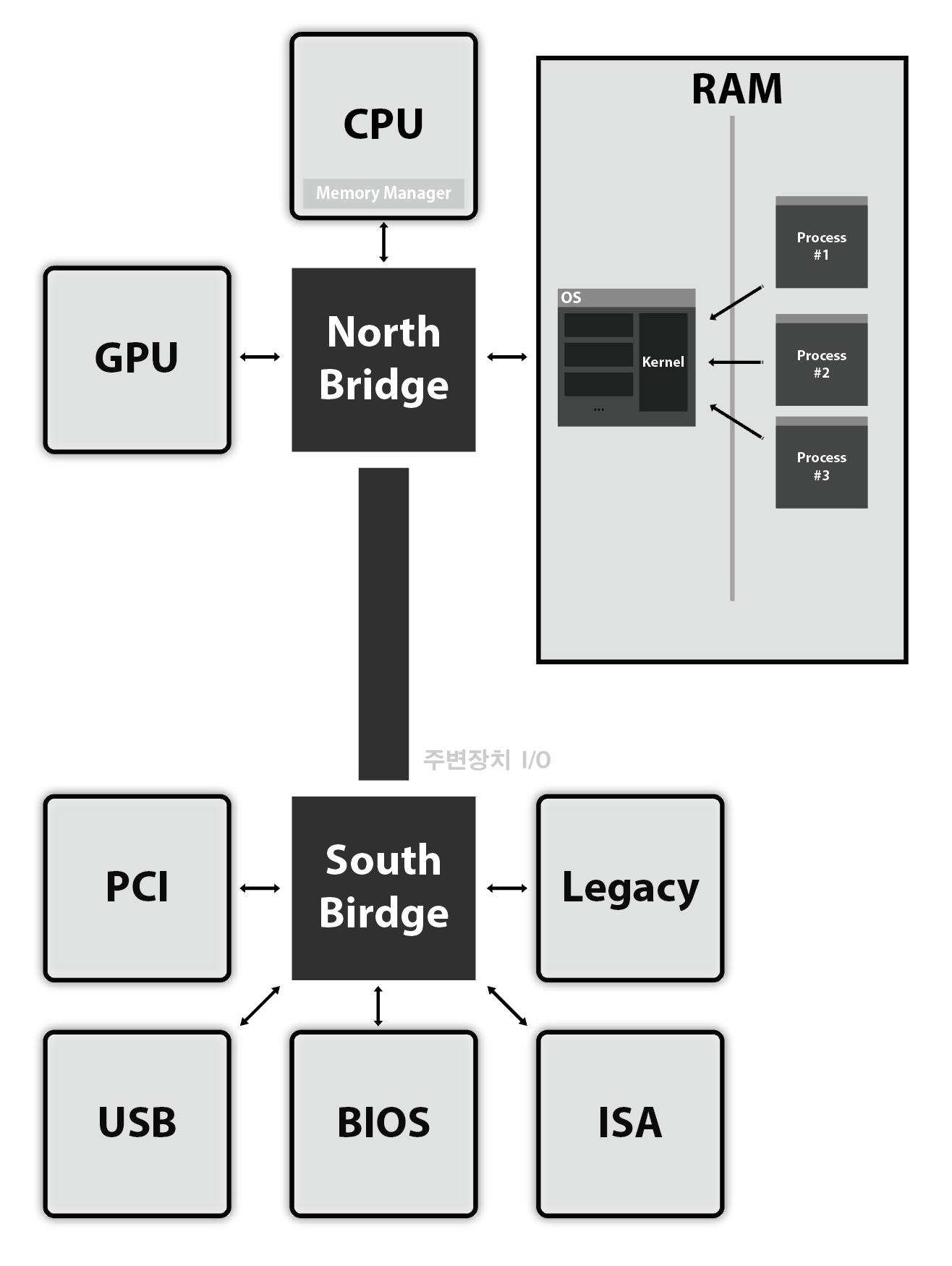
CPU 와 Memory
CPU 와 메모리간의 네트워크는
메모리 관리자(MM, MemoryManager)가 담당한다.
메모리 관리자는 메인보드 의 칩셋에 붙어있는데,
이를 BridgeChipset(브릿지 칩셋, 칩셋) 이라고도 한다.
메인보드 가 안좋으면 메모리 관리자도 성능이 좋지 않을것이며,
그렇다면 CPU 가 아무리 좋아도 제성능을 내지 못한다.
메인보드가 좋으면
브릿지 칩셋이 좋은게 붙어있고,
그럼 CPU 가 고성능, 제성능을 낼 수 있다.
대만에서 저가 브릿지를 장착시킨 메인보드를 양산하자,
Intel 에서는 아무리 좋은 CPU 를 만들어도
CPU 와 Memory 간의 성능이 좋지 않은 문제가 발생햇다.
때문에 Intel 에서 North Bridge 의 기능 일부를
CPU 를 만들면서 자체 개발하기로 했다.
컴퓨터 논리적 구조
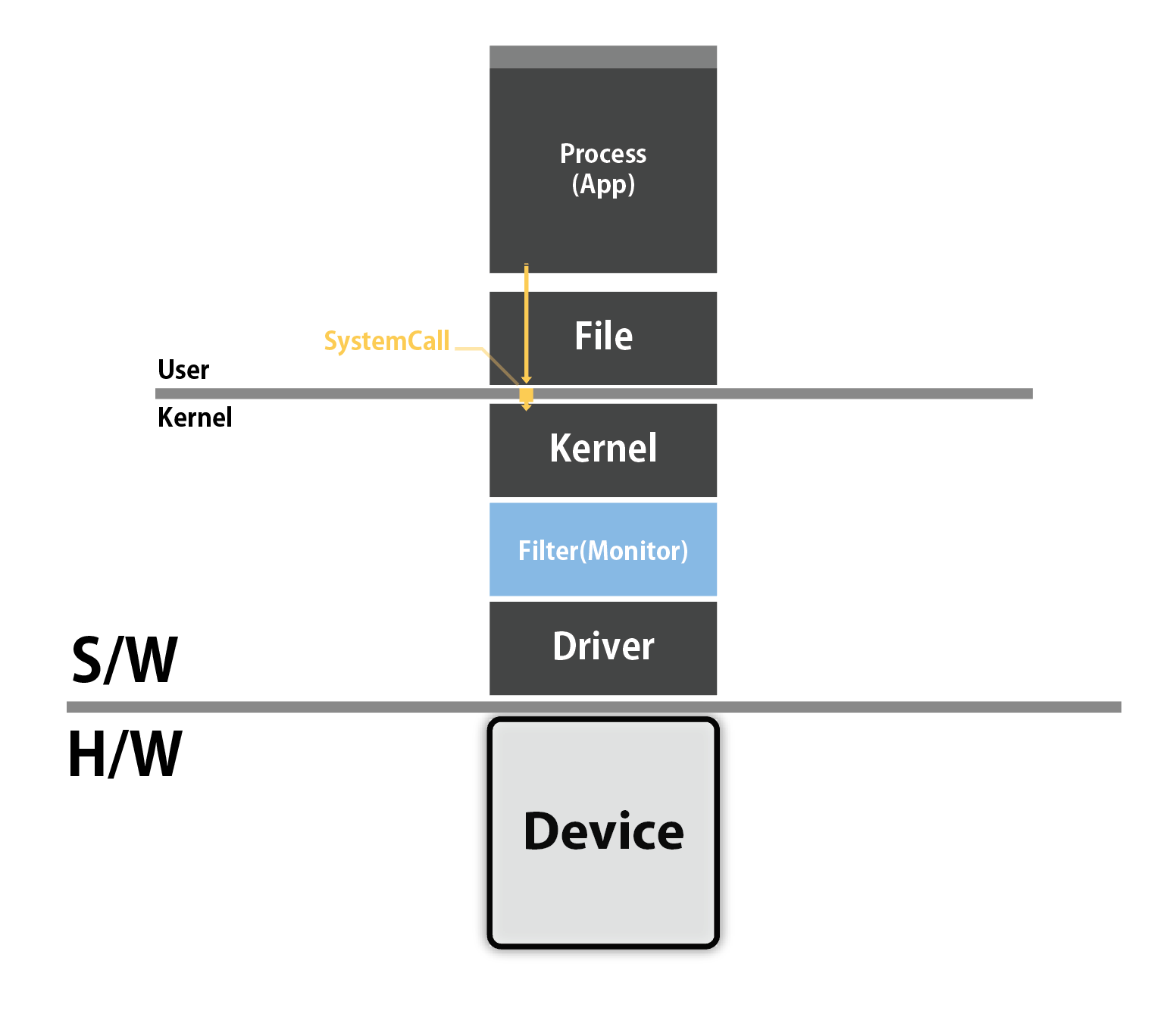
파일이란 단순히 데이터 뭉치가 아니다.
파일을 오른쪽 클릭하면
연결프로그램이라는 버튼을 볼 수 있다.
즉 파일을 통해 프로그램을 실행할 수 있고
프로그램은 개발자들이 커널 리소스를 어떻게 활용할 것인지
작성해놓은 명령어 집합, 계획서 인것이다.
즉 파일을 통해 우리는
유저모드에서 커널모드로 진입할 수 있는 수단이다.
유저모드 어플리케이션이 커널모드에 집입할 스 있는 유일한 수단이다.
다리같은
유저모드 어플리케이션이 커널모드에 진입할 수 있도록 추상화된 인터페이스가 파일이다.
다른방식으로 이야기한다면...
우리가 파일을 열어서 보는 내용은,
파일의 일부 내용에 해당한다.
파일은 특정 프로세스에 대한 인터페이스를 의미하며,
파일의 내용에는, 대상이 되는 프로세스에 전달하기 위한 정보를 저장할 수 있는데,
그 내용중에는 우리가 저장하고자 하는 내용을 담을 수도 있을것이다.
이렇게 추측할 수 있다.
즉 우리가 퍼일을 열면,
파일에 적힌 여러가지 내용을 프로세스에 전달하게 되는데,
그중에는 우리가 입력한 내용이 있으며,
프로그램은 UI 를 통해 우리가 입력한 내용을
유저에게 화면으로 전달합니다.
네트워크 에서의 파일
Process 의 구성요소, 인터페이스 를 추상화 한것이 File 이다.
NIC (NetworkInterafceCard) 을 다루기 위한 Interface,
다시말해 네트워크를 위한 하드웨어를 다루기 위한 드라이버와 상호작용하기 위한 인터페이스,
다시말해 TCP/IP ( 전송-네트워크라는 추상개념의 구현 ) 를 다룰 수 있도록 추상화 한것이 Socket 이다.
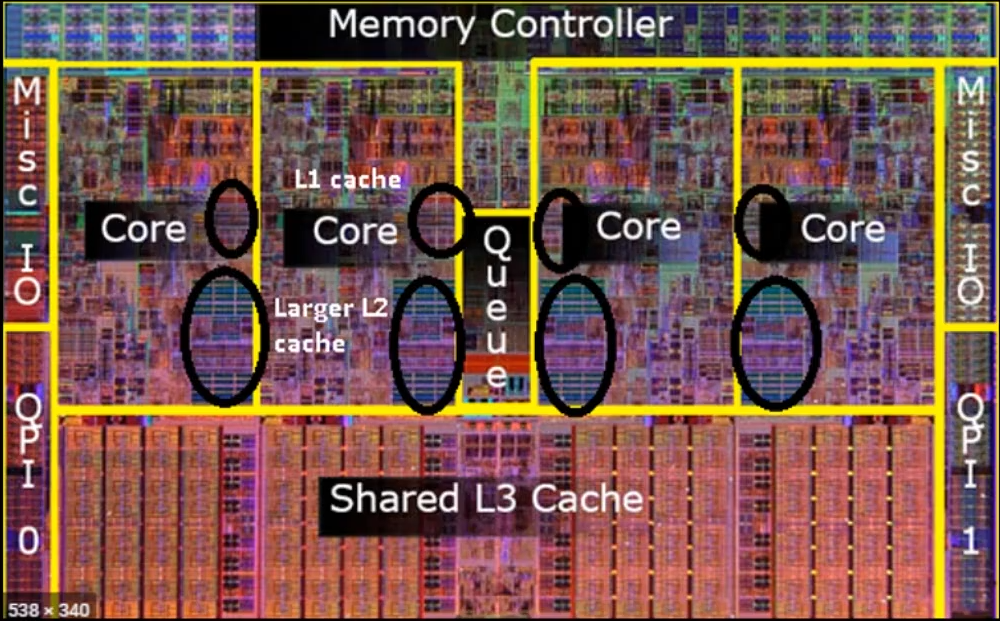
Cache & Memory
RAM 에서 CPU 로 이동하는
데이터 전송 비용또한, CPU 연산 비용에 비해 엄청나게 크다.
RAM 에서 데이터를 꺼내오는 시간에 CPU 에서는 n 번 이상의 연산을 수행할 수 있다.
우선 cache L1, L2, L3 를 순차적으로 데이터를 찾아보고 없으면 메모리에서 찾아 온다.
Core 옆에 바로 L1 Cache 가 있고,
그 밑에 L2 와 L3 Cache 가 있다.
CPU
|
Core
|
Core
|
Core
|
Core
|
|
Core
|
Core
|
Core
|
Core
|
|
<--->
|
Memory
|
캐시 철학
-
Temporal Locality
-
시간적으로 보면, 방금 주문한 테이블에서 추가 주문이 나올 확률이 높다.
방금 주문한 걸 메모해 놓으면 펀하지 않을까?
-
가장 최근에 접근한 데이터를, 또 다시 접근할 확률이 크다.
-
Special Locality
-
공간적으로 보면, 방금 주문한 사람 근처에 있는 사람이, 추가 주문을 할 확률이 높다.
방금 주문한 사람과 합석하고 있는 사람들의 주문 목록도 메모해 놓으면 편하지 않을까?
-
어떤 배열의 반복문을 돌고 있다면, i 번째 데이터를 참조했다면, i+1 번째 데이터도 참조할 확률이 크다.
미리 갖다놓으면 펀하지 않을까? 인접한 데이터가 활용될 가능성이 높다!
-
때문에 해당 데이터만 가져올것이 아니라. 그 인접 데이터를 모두 가져와 , 캐시 메모리에 적재할 가능성이 높다.
아래는 캐시가 어떤식으로 작동하는지 볼 수 있는 예시이다.
코드만 봤을때는 똑같이 10000 * 10000 번을 반복하는 코드로 똑같이 걸릴것 같지만,
캐시의 작동방식에 의해 시간차이가 3배 가량 차이난다.
// [][][][] [][][][] [][][][] [][][][] ...
int32 buffer[10000][10000];
int main()
{
memset(buffer, 0, sizeof(buffer));
// 2차원 배열도 사실 1차원 배열이며, 이를 선형으로 이어서 참조하고 있다. Cache Hit 적중률이 높다.
{
uint64 start = GetTickCount64(); // 시작점 시간
uint64 sum = 0;
for(int32 i = 0; i < 10000 ; i++){
for(int32 j =0; j < 10000 ; j++){
sum += buffer[i][j]
}
}
uint64 end = GetTickCount64(); // 끝 시간
std::cout << "Elapsed Tick : " << (end - start) << endl; // 약 100
}
// 인접한 데이터를 참조할것이라, 기대했지만, 그렇지 않아서, 시간이 더 걸린다.
{
uint64 start = GetTickCount64(); // 시작점 시간
uint64 sum = 0;
for(int32 i = 0; i < 10000 ; i++){
for(int32 j =0; j < 10000 ; j++){
sum += buffer[i][j]
}
}
uint64 end = GetTickCount64(); // 끝 시간
std::cout << "Elapsed Tick : " << (end - start) << endl; // 약 300
}
}