네이게이션바
메모내용
Synchronous And Asynchronous
요약
- File I/O
- Synchronous I/O ( 동기 )
- Asynchronous I/O ( 비동기 )
-
Overlapped I/O : OS 가 I/O 완료시 OVERLAPPED.Event 를 Set 해준다
-
Completion Routine I/O : OS 가 I/O 완료시 CallBack CompletionRoutine 함수 호출
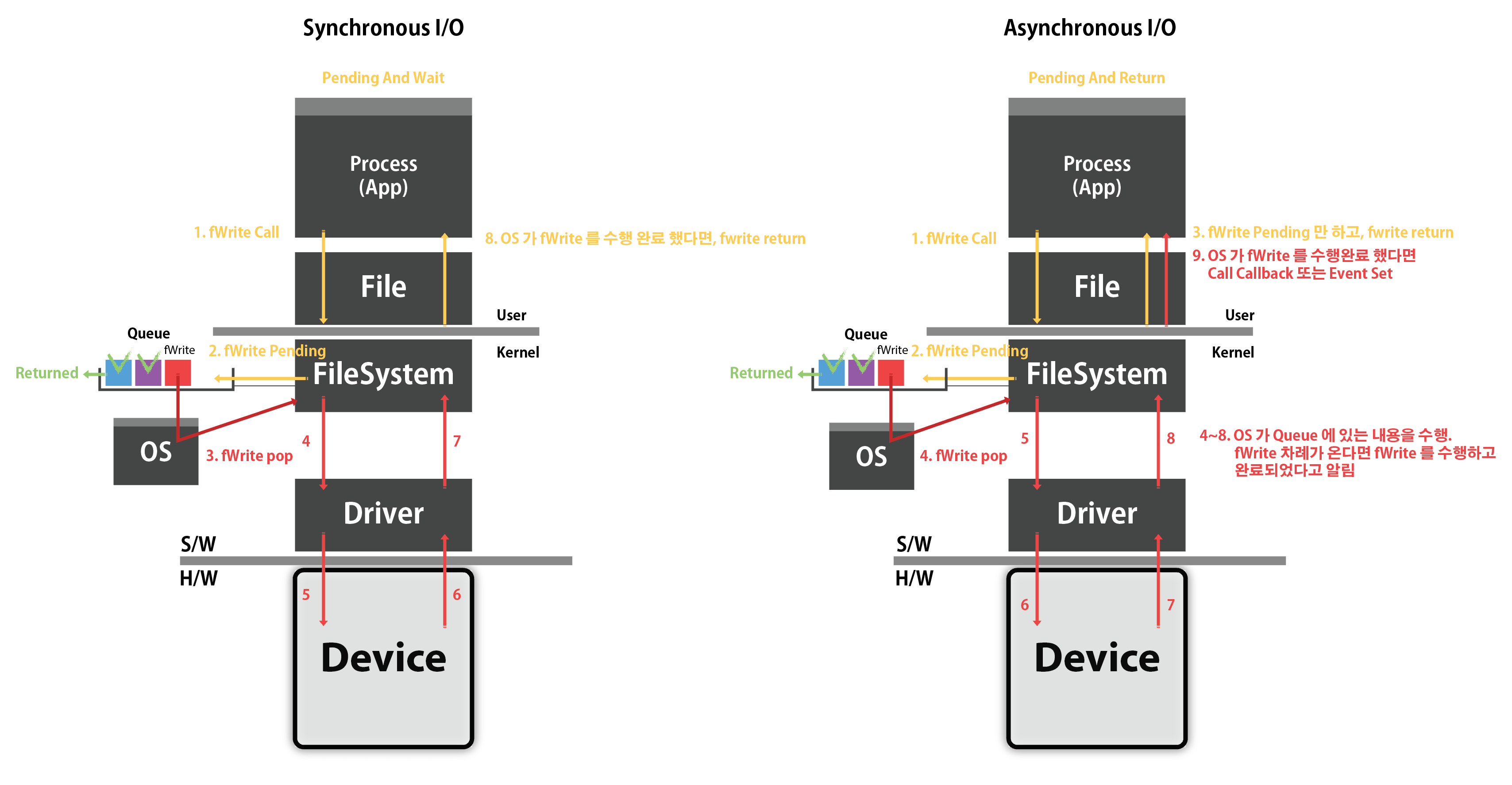
파일 입출력에는 동기 입출력과 비동기 입출력이 있다.
동기 입출력 함수는 OS 의 I/O Request Queue 에 입출력 요청을 처리하는데 필요한 데이터를 담아서 전달한 후, (OVERAPPED 사용 X)
OS가 I/O 작업을 완료할때까지 호출자가 블로킹(Wait) 한다.
OS 는 작업이 완료되면 호출자에게 결과를 반환한다.
비동기 입출력 함수는 OS 의 I/O Request Queue 에 OVERLAPPED 구조체를 담아서,
OS 가 I/O 작업시 사용하도록 한다.
OS 가 I/O 완료시 OVERAPPED 안에 있는 Event 를 호출하면 OVERAPPED I/O 이고,
( 프로세스는 이 OVERAPPED 구조체를 통해 비동기 I/O 작업을 추적하고 완료시점을 알 수 있다. 즉 OS 는 Event 를 Set 할테니 내가 감시해야한다. )
여기서는 Thread 종료전 WaitForSingleObject, WaitForMultipleObejects 로 Evnet 가 Set 되길 기다려야 한다.
I/O 완료시 OS 가 비동기 입출력 함수에 인자로 전달된 CompletionRoutine 함수를 호출하면 CompletionRoutine I/O 이다.
( 내가 EVENT 를 감시할 필요없이, OS 가 CallBack 해준다. )
여기서는 Thread 종료전 SleepEx, WaitForSingleObjectEx, WaitForMultipleObejectsEx 로 Callback 이 호출되길 기다려야 한다.
이는 ~Ex 함수가 Thread 를 Alertable Wait 상태로 빠지게 하며, 이 상태에서 Thread 의 APC Queue 에 담긴 Callback 함수가 호출되는 원리이다.
File I / O
모든 (파일에 대한) I/O 의 주체는 OS 이다.
항상 Process 는 OS 에게 파일의 입출력을 요청하는 입장이다.
입출력 요청이 queue 에 쌓이면, OS 가 하나씩 꺼내서 디스크에다가 IO 를 진행한다.
그래서, OS 가 디바이스에 I/O 를 Complete 할때까지 Wait 하는것이 적절할까 ?
이는 Application 에서 결정해야 하는 상황이다. 어떻게 할것인지 결정해야한다.
GUI 가 있거나, Server 같이 여러 IO 가 동시에 일어난다면, 기다려선 안된다.
그래서 동기 / 비동기를 논하게 될 수 밖에 없다.
파일 입출력을 요청하는데에는 1초가 걸린다면 파일 입출력 처리를 하는데에는 수초가 걸린다.
당연히 부탁이 처리 보다 더 적게 걸린다.
그래서 부탁, 부탁, 부탁, 부탁 이렇게 4번 한다면 4초밖에 안걸리고 쉬우니
하지만 모든 작업이 완료될때까지는 수분이 걸릴수도 있다.
중첩이 될 수 밖에 없다.
File 에 입출력을 하기 위해선
파일이라는것은 디바이스를 쓰는 방법이고, 파일에 입출력을 수행하면 파일포인터(위치)는 자동으로 증가한다.
그리고 그 위치를 논하는 방법은 상대위치, 절대위치(시작점으로부터 얼마정도 떨어져 있는가, offset) 가 있는데,
OS 에게 I/O Request 를 하기 위해서는,
입출력할 대상에 대한 포인터와,
파일의 시작점으로부터의 위치(절대위치) 와
사이즈를 알려주어야 한다. ( 포인터만으로는 사이즈를 가늠할 수 없으니 )
이렇게 중첩된 IO 를 하기 위해
중첩 비동기 I/O 를 지원하는 대상은 FILE, SOCKET, PIPE 등이 있다.
이들은 동기 입출력을 지원하는 함수와, 비동기 입출력을 지원하는 함수들이 있다.
예를들어 fopen 으로 생성한 File 은 중첩된 쓰기가 안되지만, CreateFile 로 생성한 File 은 중첩된 쓰기를 지원한다.
이를 아래와 같이 정리할수 있다.
| 대상 |
생성(동기 입출력을 지원하는) |
생성(비동기 입출력를 지원하는) |
동기 IO |
비동기 IO (Overlapped I/O) |
비동기 IO (Completion Routine) |
| File |
fopen
fclose
|
CreateFile
???
|
fread
fwrite
|
ReadFile
WriteFile
|
ReadFileEx
WriteFileEx
|
| Pipe |
???
??? |
CreateNamedPipe
??? |
???
??? |
ReadFile
WriteFile |
ReadFileEx
WriteFileEx
|
| Socket |
socket
closesocket
|
WSASocket
closesocket
|
recv
send
|
???
???
|
WSARecv
WSASend
|
Overlapped I/O 를 지원하는 File, Pipe , Socket 들은 생성하는 방식이 거의 똑같다.
입출력의 대상이 되는 Handle 과, 속성에 Overlapped 를 지원하도록 하는 Flag 값을 넣어주어야 한다.
반드시 FILE_FLAG_OVERLAPPED 를 넣어주어야 한다.
HANDLE CreateFileA(
[in] LPCSTR lpFileName, // 이름 ( 경로 )
[in] DWORD dwDesiredAccess, // GENERIC_WRITE, 쓰기모드 "RWX"
[in] DWORD dwShareMode, // 공유모드 , fopen 에서는 기본적으로는 안된다. 파일하나에 대해서 여러 프로세스가 접근할수 있는지 여부
[in, optional] LPSECURITY_ATTRIBUTES lpSecurityAttributes, // 거의 NULL,
[in] DWORD dwCreationDisposition,
[in] DWORD dwFlagsAndAttributes, // 파일 속성 설정 , FILE_FLAG_OVERLAPPED 를 추가해야 중첩된 쓰기가 된다. File 하나를 두고 동시에 출력하는
[in, optional] HANDLE hTemplateFile
);
HANDLE hFile = ::CreateFile(
_T("TestFile.txt"), //_T("경로") , 이는 TEXT(" ") 와 비슷하다
GENERIC_WRITE, // 쓰기모드
0, // 공유모드
NULL,
CREATE_ALWAYS, // 무조건 생성, 같은이름의 파일이 있다면 지워버리고 다시 생성, 덮어쓰기
FILE_ATTRIBUTE_NORMAL | FILE_FLAG_OVERLAPPED, // 기본속성 + 중첩된 쓰기
NULL
);
HANDLE hPipe = :: CreateNamedPipe(
PipeName, // 파이프 이름
PIPE_ACCESS_DUPLEX | FILE_FLAG_OVERLAPPED, // 읽기, 중첩된 쓰기 지원
PIPE_TYPE_MESSAGE | PIPE_READMODE_MESSAGE | PIPE_WAIT, //
PIPE_UNLIMITED_INSTANCES, // 최대 인스턴스 개수
BUF_SIZE/2, // 출력 버퍼 사이즈
BUF_SIZE/2, // 입력 버퍼 사이즈
20000, // 클라이언트 타임-아웃
NULL // 디폴트 보안 속성
)
lpSecurityAttributes 관련
파일과 권한
파일이라는것은 접근 통제의 수단이다. ( 커널에 대한 )
권한 이야기가 시작되는데, 권한은 프로세스가 갖고 있다.
프로세스의 권한은 프로세스를 실행시킨 부모 프로세스의 권한을 상속하고
파일또한 파일을 생성한 프로세스의 권한을 상속하게 된다.
동/비동기 파일 I/O
Synchronous 함수나 Asynchronous 함수나
Kernel Mode 에 있는 Queue 에 Pending 되는 것은 똑같다.
하지만 OS 가, Pending 된 요청을 수행완료 될때까지 기다리는가,
아니면 Pending 만 해놓고 바로 return 하는가의 차이다.
Chat GPT :: Synchronous & Asynchronous
동기 함수와 비동기 함수 모두 작업을 큐에 추가하여 실행을 예약하는 방식으로 동작합니다.
다만, 동기 함수는 작업이 완료될 때까지 호출자가 기다리는 반면에, 비동기 함수는 작업을 큐에 추가한 후에 즉시 호출자에게 제어를 반환합니다.
동기 함수(SyncFunction)는 호출한 함수가 작업을 완료할 때까지 호출자에게 제어를 반환하지 않습니다.
호출한 함수는 작업을 마칠 때까지 직접 제어를 유지하며, 작업이 완료되면 결과를 반환하고 호출자가 계속 진행됩니다.
동기 함수는 호출한 함수가 완료될 때까지 기다리기 때문에 호출자는 함수의 결과에 접근할 수 있습니다.
비동기 함수(AsyncFunction)는 호출한 함수가 작업을 시작하고 나면 즉시 제어를 반환합니다.
호출한 함수는 작업을 백그라운드에서 실행하며, 작업이 완료되면 호출자에게 알림을 보내거나 콜백 함수를 실행하여 결과를 처리합니다.
비동기 함수를 호출하면 호출자는 함수의 작업이 완료될 때까지 기다리지 않고 다른 작업을 수행할 수 있습니다.
이제 Kernel Mode에서 관리하는 Queue에 대해 설명하겠습니다.
동기 함수와 비동기 함수 모두 커널 모드에서 관리하는 큐를 사용할 수 있지만, 이 큐는 두 함수를 다른 방식으로 처리합니다.
비동기 함수(AsyncFunction)의 경우, 호출자가 함수를 호출하면 함수는 작업을 큐에 추가하고 즉시 반환합니다.
이후에는 백그라운드에서 해당 작업이 실행됩니다. 작업이 완료되면 호출자에게 알림을 보내거나 콜백 함수를 실행하여 결과를 처리합니다.
동기 함수(SyncFunction)의 경우, 호출자가 함수를 호출하면 함수는 작업을 큐에 추가하고 작업이 완료될 때까지 기다립니다.
작업이 완료되면 호출자에게 결과를 반환하고 호출자가 계속 진행합니다. 호출자는 동기 함수의 작업이 완료될 때까지 기다려야 합니다.
따라서, 동기 함수와 비동기 함수는 동일한 큐 메커니즘을 사용하여 작업을 큐에 추가하며, 기다릴지 여부에 따라 다른 방식으로 동작합니다.
I/O 와 CPU Clock 의 관계
|
|
---- a ---->
---- b ---->
---- c ---->
|
|
일반적으로 CPU 클럭이 높아지면, 높은 퍼포머스를 보여준다. I/O도 일반적으로 클럭 속도가 빠르면 빨리진다.
하지만 실제 I/O는 CPU 클럭과는 별도로 BUS 클럭에 의존도가 높다.
보편적으로 시스템 디자인 시, CPU 클럭이 높으면 그만큼 I/O 클럭(bus 클럭)이 높은것이 일반적이다.
그렇다면 I/O 클럭을 포함하는 CPU클럭, 즉, 시스템 클럭이 I/O와 어떤 관계를 갖을까?
예를들어 보겠다. A, B 두개의 시스템이 있다.
A라는 시스템의 목적지가 있다. A는 생성된 데이터를 가공하여 목적지로 보낸다.
B라는 시스템도 마찬가지이다. 생성된 데이터를 가공하여 목적지로 보낸다.
중요한 것은 A의 클럭은 100이고 B는 200이다.
클럭이 높으면 I/O가 빠를거라고 생각하지만 꼭 그렇지는 않다.
물론 보편적으로 시스템 클럭이 높으면 I/O클럭도 빠르긴하다.
보통 I/O를 한다고 하면 대상이 파일이건 아니면 콘솔이건 네트워크이건 무엇이건 버퍼링이라는 것을 한다.
버퍼링을 한다는 것은 버퍼가 있다는 뜻이다.
I/O 의 기본 매커니즘입니다.
버퍼를 둔 이유는 데이터를 한번에 모아서 보내면 더 빠른 시간에 많은 것을 보낼 수 있기 때문이다.
다시 예제로 들어와서 A, B 시스템 모두 버퍼가 있다고 해보자
버퍼를 비우는 정책은 프로그래머가 결정할 수 있다.
예를 들어 10클럭에 한번씩 버퍼가 비워진다고 가정해보자.
B는 200 클럭으로 작동한다. 초당 200번 클럭이 발생한다는 것이다.
그렇다면 10 클럭에 한번씩 FLUSH가 된다는 것은 1초에 20번 비워진다는 것이고
A는 1초에 10번 비워진다는 것이다.
그럼 실제로 데이터를 만들어내는 속도가 B가 더 빠르겠지만, 같다고 가정하겠다. 데이터는 a, b, c가 만들어진다.
그럼 A는 a, b, c 데이터를 모아서 묶어서 한번에 보내고,
B의 경우에는 a 생성 시 보내고, b 생성하면 보내고, c 생성하면 보내는 식으로 데이터를 보내게 될 것이다.
여기서 문제가 발생한다.
TCP/IP에서는 한번 데이터를 보내면 ACK 를 보내는 등, 보낸 데이터에 대한 검증을 받는다. 즉, 양방향 통신을 한다.
A는 이는 한번만 핸들링하면 되는데 B는 세번을 해야하는 것이다.
I/O 같은 경우에는 CPU에 비해 훨씬 느린 환경이다. 파일에 비해서도 느리다.
B가 300클럭으로 작동한다 해도, 목적지가 로컬 시스템이 아닌 외부의 다른 시스템일 경우에는
이 프로토콜을 여러번 사용한다는 것은 상당한 부담이다.
아무리 클럭속도가 빠르다 하더라도 네트워크 상에 연결된 두개의 시스템이 통신하는 시간은 줄일 수 없다.
그러므로 A가 B보다 3배의 속도를 내기도 한다.
I/O 연산이 묶이게 될 경우에는, CPU 클럭이 차지하는 영향은 상당히 작다.
버퍼를 비우는 정책은 상당히 중요하다.
즉, I/O는 독립적인 영역으로 볼 정도로 따로 봐야하는 면이 굉장히 많다.
동기, 비동기 I/O
동기 I/O
write라는 함수가 있다. 이는 데이터를 보내는 함수이다.
이 함수를 호출하는 순간 데이터의 전송이 시작된다.
wirte 함수가 끝나는 순간은 데이터 전송이 끝나는 순간이다.
즉, 함수의 호출과 데이터 전송이 동기화, 함수의 반환과 전송의 끝이 동기화 되어있다.
이게 바로 동기화 I/O이다.
비동기 I/O
wirte 함수를 호출하여 데이터 전송이 시작하는 것 까지는 똑같다.
하지만 함수를 반환하는 시점이 데이터 전송의 끝임을 의미하지는 않는다.
비동기 I/O는 wirte 함수를 호출하자마자 반환을 해버리고 내부적으로 슬슬 데이터 전송을 해나간다.
비동기 I/O 의 장점
예를 들어 보자. wirte 함수가 동기화되어있다는 것은 데이터 전송이 끝날때 까지 함수 반환을 안한다는 것이다.
그럼 그 동안 CPU는 할일이 있음에도 불구하고 할 수 없다.
비동기의 경우 write 함수를 호출하자마자 반환 되었으므로 또 다른 일을 할 수 있다.
여기서 질문이 있다. I/O연산이 계속되고 있는데 다른 일을 계속 할 수 있나?
답은 가능하다. I/O는 I/O 자체적으로 독립된 연산이다.
우리가 파이프라인을 구성할 수 있는 이유는 ALU가 연산하고 있을 때 다른 일을 할 수 있기 때문이었다.
I/O와 CPU는 일이 나누어져 있기 때문에 의존도가 높지 않다.
즉, I/O 연산 중이어도 다른 일은 얼마든지 가능하다.
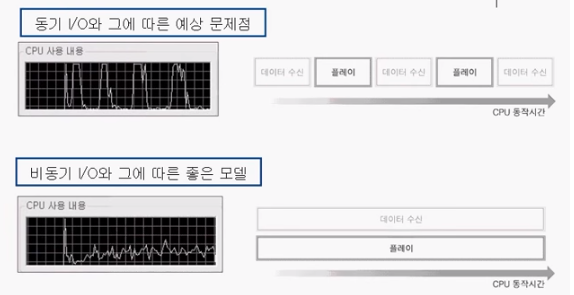
동기 I/O와 비동기 I/O에 대한 CPU 사용 내용을 보자.
위에 모델을 보면 CPU 사용률이 엄청 높다 떨어졌다를 반복한다. 떨어질 때는 CPU가 쉬고있다는 뜻이다.
이의 문제점은 CPU를 원활히 사용하지 못하는 프로그램이라는 것이다. CPU가 블러킹된 상태이다.
일을 시키지 않기 때문에 CPU도 이렇게 블러킹이 될 수 있다.
밑의 그림은 CPU 사용률이 물결친다. 이는 CPU가 계속적으로 일을 하고 있다는 뜻이다.
일반적인 프로그램의 60% 이상이 I/O에 관련된 연산이다.
즉, 이렇게 CPU가 무리도 안가게끔 여유를 두고 CPU를 지속적으로 사용하고 있다는 것은
CPU가 일할 수 있는 적절한 양을 시키면서 I/O 연산도 진행하고 있다는 것이다.
비동기 I/O 입출력을 사용할 경우 아래와 같은 CPU 사용 내역을 볼 수 있다.
보통 위에 모델이 더 구현하기는 쉽다.
보편적으로 아래 모델이 더 좋은 모델이라 하지만, 경우에 따라선 위에 모델을 사용할 수 있다.
비동기 I/O 의 종류
윈도우즈에서 제공해주는 대표적이고 일반적인 I/O 모델 두가지를 소개하겠다.
-
중첩(Overlapped) I/O
-
완료루틴 (Completion Routine) 기반 확장I/O
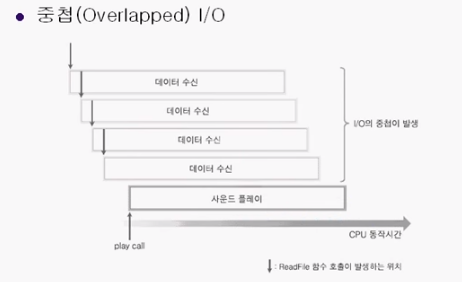
중첩(Overlapped) I/O
단순히 I/O연산이 중첩되었다는 것을 뜻한다.
read 함수가 호출되었을 때 데이터 수신이 시작된다고 가정하겠다.
근데 사진을 보면 데이터 수신이 끝나기 전에 새로운 데이터 수신이 이루어지고 있다.
이 말은 read함수 호출이 끝나자마자 새로운 read 함수를 호출했다는 것이다.
총 4개의 I/O작업이 중첩되어 있다. 이는 상당한 도움이 된다.
A, B, C가 통신을 한다. A-B, A-C가 동시에 통신을 하면 A가 느려질까?
그렇지 않다. 보편적으로 I/O는 느리기 때문에 CPU는 상대적으로 많이 기다린다.
그렇기 때문에 하나를 기다리던 두개를 기다리던 여러개 기다려도 상관이 없다.
이왕 1개를 기다리는 시간에 2개를 기다리는 것이 낫다는 것이다.
하지만 여기서 문제가 있다 보편적으로 각각이 I/O 작업을 할 때, I/O가 완료가 되면 하다못해 파일에라가도 저장을 해야한다.
즉, I/O연산이 끝나면 그에 대한 부가적인 작업이 있다는 것이다.
I/O 연산이 끝나면 어떤 것의 연산이 끝났는지 확인을 해야한다는 것이다.
이는 비동기이므로 상당한 부담이 될 것이다.
각기 I/O 에 따른 부가적인 작업이 다르고 이를 구분하기 너무 어렵다는 것이다.
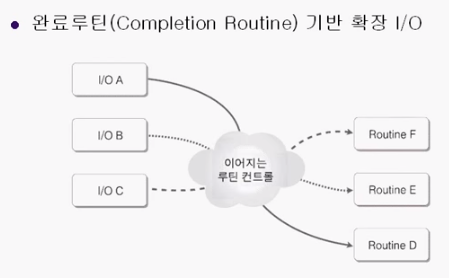
이 문제를 해결하기 위해 나온 것이 완료루틴 기반 확장 I/O이다.
완료루틴 기반 확장 I/O
뭐가 가능하냐
A I/O , B I/O , C I/O가 끝났을 때 각각 실행되어야 하는 루틴(함수 호출) 을 묶어 놓을수가 있다는 것이다.
그러면 각 A, B, C I/O 가 끝났을때, 자동적으로 D, E, F 를 자동적으로 실행해줄수 있다.
연산이 끝났을 때 그에 대한 부가작업, 즉, 어떤게 끝났는지 확인하는 일에 대한 부담을 덜어줄 수 있다.
이것이 Completion Routine I/O 이다.
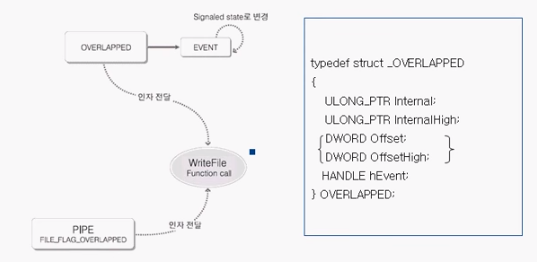
Overlapped I/O 구현
Overlapped I/O 에서는 OS 가 I/O 를 처리하면 Overlapped 에 있는 Event 를 Set 해준다.
중첩 I/O를 구현하기 위해선, 위에 그림을 머릿속에 떠올리는 것이 좋다.
이를 이렇게 정리하지 않으면 어떻게 해야할지 혼란스러울 때가 많기 때문이다.
중첩 I/O를 구현하기 위한 첫번째 포인트는 일반적인 I/O함수를 호출하는 것이다. 여기서는 WriteFile함수를 쓰면 된다.
WriteFile함수의 전달 인자를 보면 OVERLAPPED 구조체가 있다.
이 인자는 중첩 I/O를 하겠다는 것을 알리는 효과를 갖는다. 또한 중첩 I/O에 대한 정보를 담을 수 있다.
중첩 I/O 가 아니면 COMPLETION ROUTINE I/O가 있는데, 이는 중첩 I/O를 확장한 것이다.
따라서 그것도 중첩 I/O라 할 수 있다. 그래서 둘 다 이 구조체를 초기화 해주어야 한다.
그림의 오른쪽을 보면 OVERAPPED 구조체를 볼 수 있다.
Overlapped 구조체
OVERAPPED
- 비동기 I/O 요청 의뢰서-
-
작업 진행사항 : [ 작업 접수됨 ]
-
I/O 수행해야할 위치 : offset
-
입출력한 데이터 양 ________ byte
-
완료시 설정할 이벤트 : hEvent
-
...
비동기 IO 요청에 필요한 정보를 담은 구조체.
쉽게 말하면, 당장 IO 수행해야 하는거 아니니까. 까먹을 수 있으니
파일의 어디 부분에 IO 를 해야할지, 참고해야할 사항(데이터) 를 적어놓은 종이.
OS 는 이것을 비동기 IO 요청을 모아놓는 I/O Request Queue 에 담아놨다가
나중에 수행할때 이것을 보고 IO 작업을 하게 된다.
그리고 수행하고 나면, 이 종이를 다시 준다.
(적어준대로 작업 했다고, 확인해보라고 다시 돌려주는 느낌)
ReadFile, WriteFile 함수에 사용된다.
함수호출에서 이 구조체를 사용하려면, 구조체의 사용되지 않는 멤버는, 항상 0 으로 초기화 해야 합니다.
그렇지 않으면 함수가 실패하고 ERROR_INVALID_PARAMETER 를 반환할 수도 있다.
이 구조체는 재사용해서는 안된다. 각 요청에 대해 별도의 구조체를 사용해야 한다.
데이터를 처리하는 각 스레드에 대한 이벤트 객체를 따로 만들어야 한다.
WaitForMultipleObejects 함수를 사용하여 모든 이벤트가 신호를 받을때까지 쉽게 기다릴 수 있다.
OS :: I/O Request Queue
대부분의 운영 체제(OS)는 I/O 요청을 처리하기 위해 내부적으로 I/O 요청을 모아놓은 큐(queue)를 사용합니다.
이 큐는 디스크, 네트워크, 키보드 등 다양한 입출력 장치로부터의 요청을 관리하며,
이를 처리하는데 사용되는 작업 스케줄링 알고리즘에 따라 순서대로 처리됩니다.
I/O 요청 큐는 입출력 작업의 효율성과 공정성을 향상시키기 위해 사용됩니다.
예를 들어, 여러 개의 프로세스가 동시에 I/O 작업을 요청할 경우,
운영 체제는 이러한 요청들을 큐에 저장한 후에 적절한 순서로 처리합니다.
이를 통해 입출력 작업의 우선순위를 결정하고, 시스템 자원을 효율적으로 활용할 수 있습니다.
또한, I/O 요청 큐는 입출력 작업의 일관성과 안정성을 유지하기 위해 사용될 수도 있습니다.
예를 들어, 디스크의 경우 여러 개의 I/O 요청이 동시에 발생할 수 있으나,
디스크 헤더의 이동 등의 물리적 제약으로 인해 순차적으로 처리되어야 합니다.
따라서 I/O 요청 큐는 이러한 순차성을 유지하면서 안정적인 작업 처리를 도와줍니다.
요약하자면, 운영 체제는 I/O 작업을 관리하기 위해
I/O 요청 큐를 사용하여 입출력 요청을 모으고 처리 순서를 결정합니다.
이를 통해 시스템의 효율성과 안정성을 향상시킬 수 있습니다.
I/O 요청 큐에 들어가는 I/O Request의 구조체 형식은 운영 체제와 사용되는 I/O 모델에 따라 다를 수 있습니다.
하지만 일반적으로 Windows 운영 체제에서 사용되는 I/O 모델에서는 OVERLAPPED 구조체가 자주 사용됩니다.
OVERLAPPED 구조체는 비동기 I/O(Asynchronous I/O) 작업을 수행할 때 사용되는 구조체입니다.
비동기 I/O 작업은 I/O 요청을 발송한 후, 해당 작업이 완료될 때까지 다른 작업을 수행할 수 있는 방식입니다.
이를 위해 OVERLAPPED 구조체는 I/O 작업의 상태와 완료 여부 등을 추적하는 데 사용됩니다.
OVERLAPPED 구조체는 일반적으로 다음과 같은 멤버를 포함합니다:
- hEvent: I/O 작업 완료 시 신호를 보내기 위한 이벤트 핸들.
- Internal: I/O 작업에 대한 내부 정보.
- InternalHigh: I/O 작업에 대한 추가적인 내부 정보.
- Offset: 파일 내에서의 I/O 시작 위치.
- OffsetHigh: 파일 내에서의 I/O 시작 위치의 상위 32비트.
- Pointer: 사용자 지정 데이터 포인터.
이러한 OVERLAPPED 구조체는 비동기 I/O 작업을 수행할 때 운영 체제에게 I/O 요청을 전달하는 데 사용됩니다.
운영 체제는 이 요청을 받아 큐에 저장하거나 필요에 따라 다른 자료 구조에 저장할 수 있습니다.
따라서 I/O 요청 큐에 들어가는 구조체가 OVERLAPPED인지 여부는 운영 체제와 I/O 모델에 따라 다를 수 있습니다.
! 참고로 !
OS 가 OVERAPPED 구조체를 사용하고 있는데 UserMode 에서 OVERAPPED 구조체를 해지 해버린다면,
OS 가 잘못된 주소로 접근하게 되고, OS (Kernel)가 다운되고 블루스크린이 뜰 것이다.
그래서, OS 는 UserMode Application 의 Resource 에 접근할 일이 생기면,
UserMode 에서 건드리지 못하도록 Lock 을 걸어버린다.
그리고 자기가 할일이 끝나면 UnLock 을 해준다.
OS 에는 I/O Request 를 Queue 에 차곡차곡 담아서, 처리한다. ( OS 니까 MultiThread 활용 하겠지? )
여기에 담긴 Request 가 OVERAPPED 이다.
그리고 I/O 가 끝나면 Overlapped 에 담긴 Event 를 Set 해준다.
OS :: I/O Request Queue
|
OVERAPPED
|
OVERAPPED
|
OVERAPPED
|
...
|
|
struct _OVERLAPPED{
ULONG_PTR Internal; // I/O 요청 수행 상태
ULONG_PTR InternalHigh; // 전송된 바이트 수
DWORD Offst; // 파일내에서의, I/O 시작 위치
DWORD OffetHigh; // 파일내에서의, I/O 시작 위치
HANDLE hEvent; // 완료시 OS 가 Set 해주는 이벤트 핸들
} OVERLAPPED;
-
Interal
-
I/O 요청에 대한 상태 코드
-
I/O 요청이 실행되면 시스템은 이 멤버를 STATUS_PENDING 으로 설정하여,
작업이 아직 시작되지 않았음을 나타냅니다.
요청이 완료되면 시스템은 완료상태코드로 설정합니다
-
InternalHigh
-
I/O 요청에 대해 전송된 바이트 수 입니다.
-
오류없이 요청이 완료된 경우 시스템에서 이 멤버를 설정합니다.
-
Offset, OffsetHigh
-
I/O 요청을 시작할 파일 위치 ( Offset : 하위부분 , OffsetHigh : 상위부분)
-
파일 내부에서 전송이 시작되어야 할 위치
-
시작점으로부터 바이트 단위로 offset
-
OVERLAPPED 구조체를 사용하는 프로세스가 ReadFile 또는 WriteFile 을 호출하기 전에 이 값을 설정해야한다.
-
파일이 아닌 디바이스에 대해서도 체크되므로 이 경우는 0으로 초기화 해주어야 한다.
그렇지 않으면 GetLastError() 에서 ERROR_INVALID_PARAMETER 가 리턴된다.
-
hEvent
-
작업이 완료될때 신호를 받는 이벤트에 대한 핸들
-
OVERLAPPED 구조체를 전달하기 전에 CreateEvent 함수를 사용하여, 이 멤버를 0 으로 초기화 하거나, 유효한 이벤트 핸들로 초기화해야 한다.
그래야, 이 이벤트를 사용해서 디바이스에 대한 중첩(동시)된 I/O 요청을 동기화 할 수 있다.
관련함수
-
HasOverlappedIoCompleted : I/O 요청이 완료 되었는지 여부 확인
-
CancelIo : I/O 작업 취소
참고
주의를 기울여야할 인자는 hEvent 이다. I/O가 끝났다는 것을 확인할 수 있다.
internal은 내부적으로 선언된 것이므로 신경안써도 되고
offser, offsetHigh 는 file I/O에서 파일 포인터를 이동하는데에도 사용이 된다.
반드시 기억해야 할 것은 일단 hEvent 함수 하나이다.
그럼 초기화 하는 방법은 간단하다. 전체를 초기화 하고 EVENT 오브젝트를 생성하여 hEvent에 저장해주면 된다.
I/O 작업이 끝난 이후에는 자동적으로 EVENT가 signaled 상태로 바뀌며 작업을 시작한다.
WriteFile 함수를 호출하는데 두가지가 필요하다.
일단 OVERAPPED 구조체의 변수와 실제 i/o를 누구와 할지 핸들 정보를 알려주어야 한다.
여기서 전달된 인자를 가지고 I/O 작업을 하는데 WirteFile 함수의 정보를 통해 비동기로 작업을 확인하고,
I/O 작업이 끝난 이후에는 자동적으로 EVENT가 작업을 시작한다.
// 1. 비동기 입출력 대상 생성
HANDLE hFile :: CreateFile( ... )
// 2-1. Overlapped 구조체 생성 및 초기화(memset)
OVERAPPED Overlapped;
// 2-2. Overlapped 구조체에 묶어줄 Event 생성
HANDLE OverlappedEvent = CreateEvent(...);
// 2-3. Overlapped 구조체에 이벤트 묶기
Overlapped.hEvent = OverlappedEvent;
// 3. 비동기 입출력 함수 호출 ( 입출력 대상 HANDLE 과 , Overlapped 구조체 )
WriteFile(
hFile,
...
Overlapped
)
// 4. Overlapped 구조체에 묶어준 이벤트 기다리기
WaitForSingleObject(Overlapped.hEvent, INFINITE);
// 5. 완료되면 결과 확인하기
GetOverlappedResult(hFile, &Overlapped, 전송된데이터양을 받을 버퍼, FALSE );
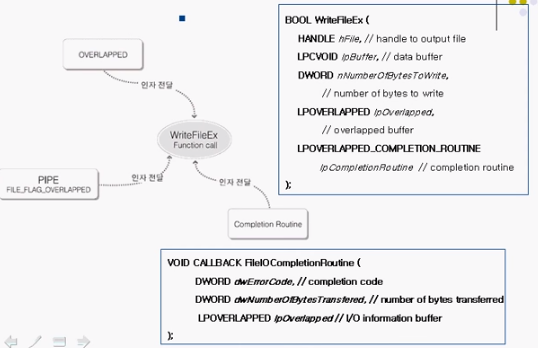
Completion Routine I/O 구현
Overlapped I/O 에서는 OS 가 I/O 를 처리하면 Overlapped 에 있는 Event 를 Set 해주었지만,
Completion Routine I/O 에서는 OS 가 I/O 완료시 Callback 함수를 호출한다.
OS 가 호출해주기 때문에 CallBack 함수를 호출하는 코드는 절대 등장하지 않는다.
-
3 개 인자 필요
- IO 대상 핸들
- OVERAPPED 구조체
-
IOCompletionRoutine 함수 : OS 가 자동적으로 호출해준다. ( OS 가 인자까지 넣어서)
-
DWORD dwErrorCode : 에러가 발생했다면 코드로 알수 있다.
-
DWORD dwNumberOfBytesTransfered : 전송한 총 byte 데이터 양을 반환
-
LPOVERLAPPED LPOVERLAPPED : 우리가 비동기 입출력 함수를 부를때 넣어준 Overlapped 를 그대로 받을수 있다.
-
hEvent : 여기에 이벤트 핸들대신 넣어준 아무 값이나 그대로 받을 수 있다. Event 가 필요없으니, 전달인자로서 활용 가능
A 연산(I/O연산)이 끝나고 나면 그에 대한 루틴(함수)가 자동적으로 시작되게 하겠다.
이 부분이 앞에 모델에서 추가된 것의 전부이다. 그걸 WriteFileEx 함수에서 확인할 수 있다.
WriteFile 함수 대신에 WriteFileEx 함수를 호출해야 한다.
WriteFileEx 함수에는 Completion Routine을 인자로 전달해서 I/O를 연결하는 역할을 하나 더 갖고있다.
I/O연산이 끝났다는 것은 Completion Routine이 자동적으로 호출되면서 알 수 있다.
따라서 OVERAPPED 구조체의 Event Handle이 불필요해지는 것이다.
그럼 굳이 그걸 넘길필요가 있는가? 필요가 있다.
OVERAPPED 안에는 내부적으로 필요한 변수가 있으므로 반드시 전달해주어야 한다.
Completion Routine은 그림의 하단 코드와 같이 전달해주면 되는데, 우리가 전달하는 것이 아니다.
CompletionRoutine은 윈도우즈 시스템에 의해 자동적으로 호출된다. 즉, callback 함수이다.
실제로 함수를 호출하는 것이 윈도우즈면, 인자를 전달해 주는 것도 윈도우즈다.
어떤 에러가 발생했는지, 몇 바이트가 최종적으로 전달되었는지 그 바이트 수, 우리가 전달한 Overlapped 구조체 등이 인자로 전달된다.
Alertable State
알림 가능한 상태 진입을 위한 함수
SleepEx( INFINITE, TRUE ) 함수를 호출한 thread 는 Alertable State 상태가 된다. (2번째 인자로 TRUE 값을 주면, Alertable 상태가 된다. )
또한 WaitForSingleObjectEx , WaitForMultipleObejectsEx 함수도, Alertable State 상태로 진입하도록 한다.
이 3가지 함수는 Completion Routine 의 실행에 우선순위를 두겠다는 의미로 받아들여진다.
이는 Completion Routine 이 완료되었으면 하는 시점에서 반드시 호출해주어야 한다.
그렇지 않으면 Completion Routine 이 완료되었음에도 호출되지 않는 문제가 생긴다.
DWORD SleepEx(
DWORD dwMilliseconds, // time-out interval
BOOL bAlertable // true 전달시 Alertable State 상태로 진입
)
DWORD WaitForSingleObjectEx(...)
DWORD WaitForMultipleObejectsEx(...)
A가 I/O 요청했다. 이 I/O가 연산이 끝나면 CompletionRoutine 함수를 호출한다.
즉, A I/O 작업이 끝나면 자동적으로 CompletionRoutine 함수 시작될 것이기 때문에 A는 작업을 계속해야 한다.
근데 I/O 작업이 언제 끝날지는 모른다.
I/O 연산 끝나면 CompletionRoutine 을 하러 가야하는데, 프로그래머 입장에서 보면 일을 하다가 CompletionRoutine 에게 우선순위를 뺏기는 셈이다.
이 일의 우선순위를 A에게 줄지, CompletionRoutine에게 줄지 결정할 수 있어야 한다.
이게 가능해야 안정적으로 SW를 디자인할 수 있다.
만일, I/O 작업이 끝나 CompletionRoutine을 해야할 때, 지금 하고 있는 일에 상관 없이 CompletionRoutine에 우선순위를 주어
CompletionRoutine을 시작하도록 하고 싶다.
이 상태를 알람이 가능한 상태, Alertable State라 한다.
그러면 이를 명시적으로 선언해야 하는데, 이게 그림의 밑에 세가지 함수이다.
이 함수들을 호출하면, I/O 작업이 끝났을 때 CompletionRoutine이 시작하게 할 수 있다.
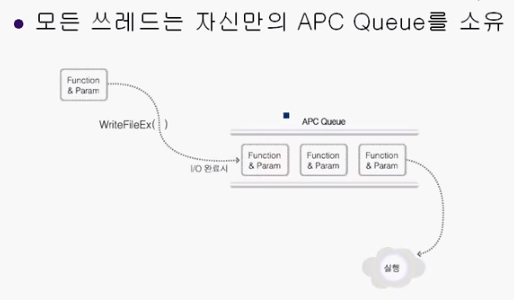
APC (Asynchronous Procedure Call)
비동기 함수 호출 매커니즘
모든 Thread는 자신만의 APC Queue 를 소유하고 있다.
APC Queue 에는 , Thread 가 알람가능한 상태가 되었을때 호출 해주어야 할 CallBack 함수들을 모아놓은 Queue 이다.
Thread 가 Alertable State 에 진입했을때 Queue 에 있는 모든 Callback 함수는 호출되고, Queue 완전히 비워진다.
(3개 함수가 있다고 해서 Alertable State 상태를 3번 진입해야 하는것이 아니라, 한번 진입했을때 모든 CallBack 을 호출한다.)
WriteFileEx 도 비동기 입출력이 완료되었을때,
호출당시 입력된 CallBack (Completion Routine)함수를 , APC Queue 에다가 추가준다.
이러한 원리를 통해 비동기 호출, Completion routine 이 완성이 된다.