가상 메모리, 가상주소, 페이징, 세그멘테이션
개요
예를들어 8GB 의 DRAM 을 2개 장착하여 사용하고 있다고 하자. 총 16GB 의 메인메모리 용량이 확보된 것이다. 언리얼 엔진을 켜고 게임을 만들다 보면 이게 16GB 안에 다 들어간다고? 싶을때가 많다. 언리얼 엔진 하나만 해도 메모리 사용량이 엄청난데, 그 와중에 게임도 구동을 해야 한다. 심지어 노래를 켜고 인터넷 검색을 하거나 동영상을 틀어놓고 하기도 한다. 어쩔 땐, 예제 프로젝트를 참고하기 위해 2~3개의 언리얼 엔진 프로젝트를 켜고 작업하기도 한다. 상식적으로 생각했을 땐, 16GB 라는 메모리 용량은 턱없이 부족할 것 같다는 생각이 들것이다. 물론 실제로도 부족하다. 부족한데 어떻게 그 모든 프로그램들을 감당할 수 있는 것일까? 이는 가상메모리 라는 기술 덕분이다. 가상메모리 기술 덕분에, 프로세스마다 할당된 공간은 다른 프로세스가 침범이 불가능 하여 안정성 향상이라는 장점도 얻게 되며, 가상 메모리의 크기가 물리 메모리보다 클 경우, 물리 메모리보다 큰 프로세스를 돌릴 수도 있다. 가상메모리의 크기는 os 의 종류에 따라 달라진다.
| 32bit(×86) Window |
4GB ( Kernel 2GB + Application 2GB )
32bit 운영체제가 접근할 수 있는 2³²개 메모리 주소 및 사이즈 4GB
|
| 64bit Window |
16TB ( Kernel 8TB + Application 8TB )
64bit 운영체제가 접근할 수 있는 2⁶⁴ 개 메모리 주소 및 사이즈 16EB
하지만 현재 chipset 에서 프로그램이 실제쓰는 가상주소는 48비트 까지만 지원하는 상황
|
가상메모리
가상메모리의 아이디어는 이렇다 4GB 짜리 프로세스를 메모리에 올리더라도, 한번에 사용되는 공간은 4GB 가 되지 않을텐데, 그러면 사용되고 있는 만큼만 메모리에 나누어서 올리면 되지 않을까?
프로세스가 전체적으로 필요한 용량은 4GB 라고 하더라도, 동시에 4G 가 모두 사용되지는 않는다. 그러므로 지금 당장 사용되는 만큼만 메모리에 적재하고 나머지는 적재하지 말자는 개념으로 시작된것이 가상메모리 이다. 하지만 프로세스는 실행되는 순간부터 모든 정보가 어딘가에는 저장이 되어 있어야 한다. 메모리에 저장을 안할거면 어디다가 할까? 바로 보조 기억장치이다. HDD, SDD 와 같은 저장장치의 도움을 받아 가상메모리를 구현하게 된다. 모든 정보를 일단 보조 기억장치에 적재해둔 뒤, 지금 당장 필요한 부분만 꺼내서 메인메모리에 적재하고 사용되지 않게 되면 다시 보조 기억장치로 적재하는 방식인 것이다. 그렇다면, 어떤 방식으로 보조 기억장치와 메모리 사이에서 정보를 옮기는 것일까? 가상 메모리를 실현하는 방법은 페이징, 세그멘테이션 2가지 기법이 있다.
페이징
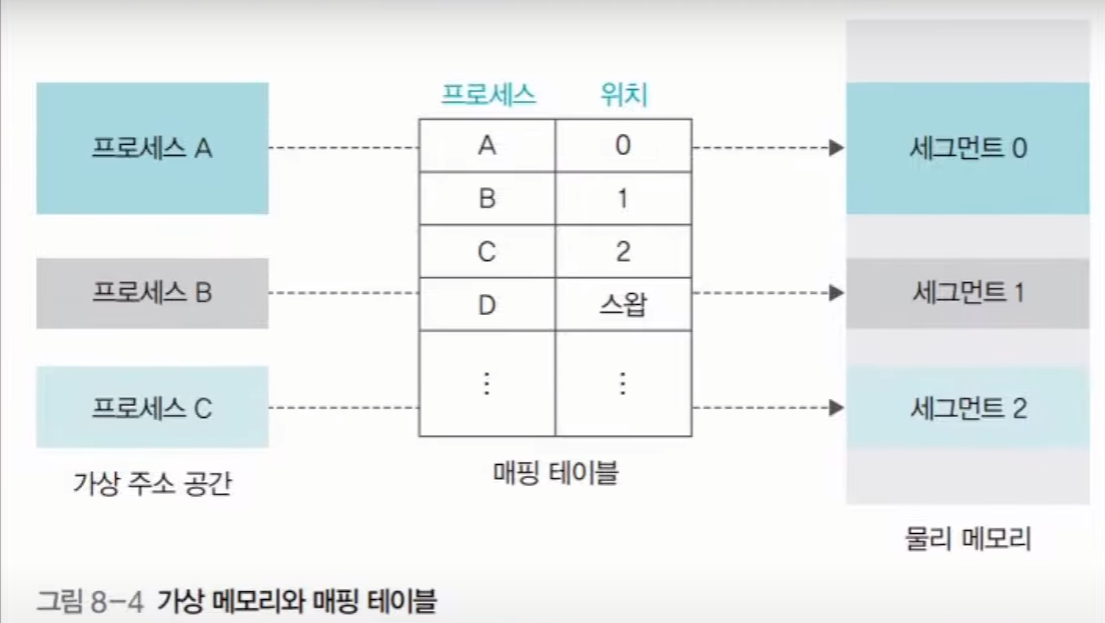
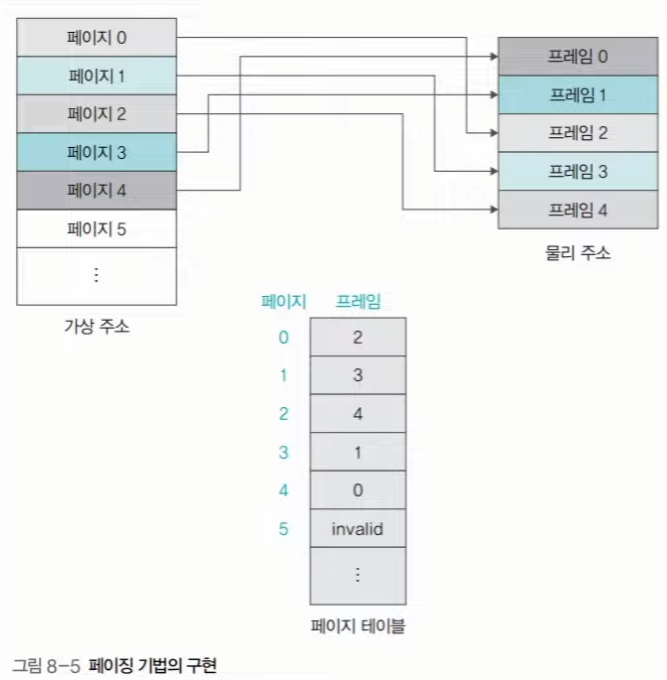
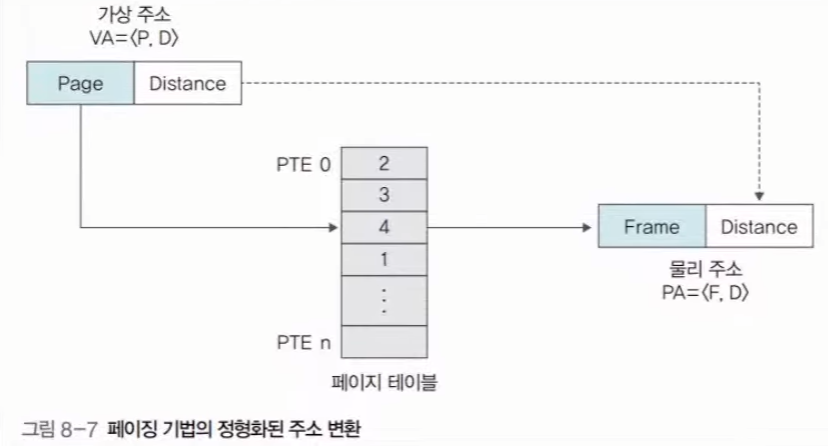
먼저 프로세스와 메인메모리를 동일한 크기로 조각을 낸다. 예를 들어, 1byte 로 쪼갠다고 한다면, 하나의 페이지는 하나의 프레임에 저장될 수 있을 것이다. 프로세스의 페이지는 각 프로세스마다 0번부터 시작하여 인덱스가 매겨진다. 반면 메인메모리는 하나이기 때문에 0번 페이지가 0번 프레임에 매칭되는 것은 아니다. 페이지는 메인메모리의 어느 프레임으로 매칭이 될 것이며, 해당 정보는 운영 체제가 보유한 페이지 테이블에 저장이 된다.
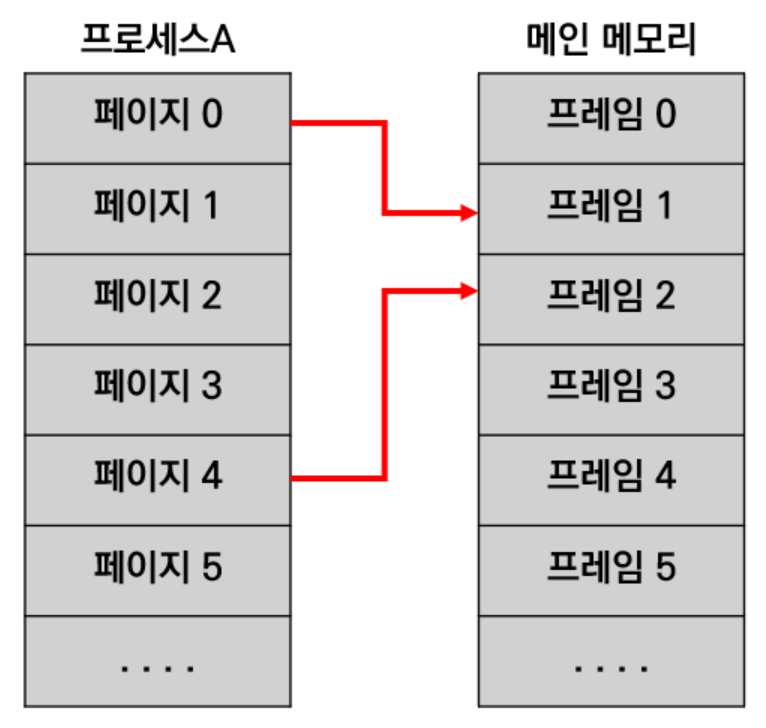
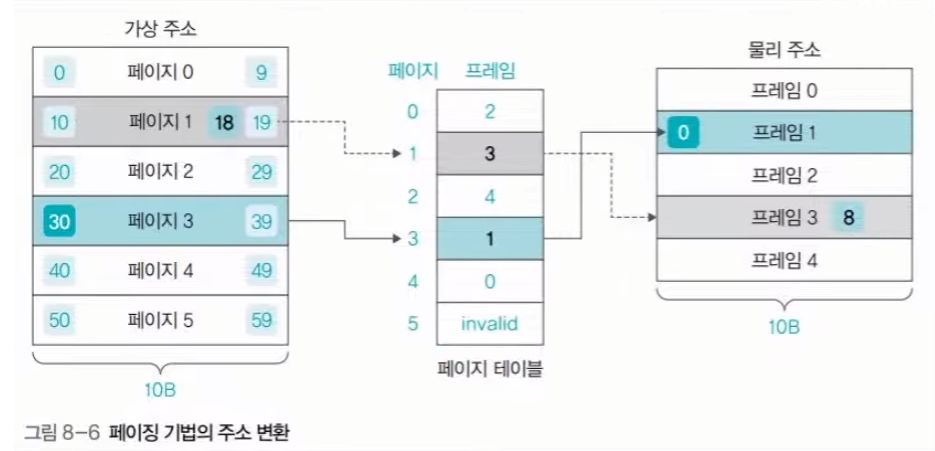
프로세스 A 가 실행되면서, 0번페이지에 있는 정보와 4번 페이지에 있는 정보가 지금 필요하다고 해보자. 그렇다면, 메인메모리의 어느 프레임에 0번 페이지와 4번 페이지의 데이터를 적제하게 될 것이다. 위에서 말했듯이, 페이지의 인덱스와 프레임의 번호는 항상 일치하는 것이 아니다. (오히려 일치하지 않는 상황이 더더욱 많다.) 그렇기 때문에, 어떤 프레임에 어떤 페이지가 적제되어 있는지 정보를 저장할 곳이 필요하다. 이것이 운영체제(OS) 가 보유한 페이지 테이블 이다. 하지만, 이렇게 쪼개져있고 위치도 계속 왔다갔다 하는 상황이라면, CPU 에선 무엇을 기준으로 주소를 인식해야 할까? 프로세스의 시작점을 기준으로 가상주소 를 부여하는 것이다. 예를 들어, 메인메모리의 주소와 동일한 개념으로 보았을 때 페이지 하나에 10개의 주소가 포함되어 있다고 해보자. 그렇다면, 페이지 0 에는 0~9번지가 있으며, 페이지 1에는 10~19 번지가 있고, 페이지 2 에는 20~29 번지가 있다고 할 수 있을 것이다. 이처럼 하나의 프로세스 시작을 0 으로 해서, 주소를 생성해 준다. 이렇게 만든 주소가 가상주소 이다. 실제로 메인메모리에 적재되면, 가상 주소와는 다른 물리 주소 를 보유하게 된다. (실제 메모리 주소) CPU 에선 해당 가상주소를 기준으로 작업을 처리하게 된다. 예를 들어, 가상주소가 5번지인 데이터가 있다면, 메인메모리의 몇 번지에 적재되어 있든간에 5번지의 데이터를 요구하는 것이다. 가상주소를 특정 방법을 통 물리주소로 변환하고, 메인메모리에선 해당 물리 주소의 데이터를 CPU 에 전달하게 된다. 하지만 페이징 기법에는 몇가지 단점이 존재한다.
페이징 기법의 단점
1. 마지막 페이지에서 내부 단편화가 발생
하나의 프로세스를 동일한 크기로 쪼개는 과정을 거치는 페이징은 프로세스의 크기가 페이지 1개 크기의 배수가 아니라면, 프로세스의 마지막 페이지는 페이지의 크기를 전부 채우지 못한다. 예를 들어, 한 페이지가 10byte라고 가정하고 프로세스 A는 91Byte라고 해보자. 마지막 페이지에선 1Byte만 사용하게 되고, 9Byte만큼의 내부 단편화가 발생하게 된다.
2. 페이지 테이블 크기만큼의 메모리를 추가로 소모해야 함
프로세스의 크기가 클수록, 페이지의 크기가 작을수록 페이지 테이블의 크기는 더욱 커질 것이다. 페이지 테이블은 메인 메모리에 항상 적재되어 있기 때문에 페이지 테이블 크기만큼의 메모리 공간을 활용할 수 없게 된다.
3. 메모리에 두 번 접근해야 함
메모리에 접근하는 시간은 CPU를 기준으로 보았을 때 매우 느린 시간이다. 이를 커버하기 위해 캐시라는 저장 장치를 활용할 정도로 CPU입장에선 메모리에 최대한 직접 접근하지 않는 것이 좋다. 하지만, 페이징 기법의 경우엔 페이지 테이블에 한 번 접근하여 물리적 주소를 알아낸 후, 실제 물리적 주소에 접근하는 두 번의 과정을 거쳐야 한다. 이는 상당한 오버헤드로 다가올 수 있다. 하지만, 실제로는 이를 해결하기 위해 TLB라는 버퍼를 사용하고 있다. 물론, 문제를 완전히 해결하는 것은 아니고 CPU의 캐시와 동일하게 최근에 사용된 페이지 테이블의 데이터를 가져와서 빠르게 탐색하는 용도로 사용한다. 캐시 미스 발생시 메모리에서 데이터를 다시 복사하는 것처럼, TLB또한 TLB 미스 발생시 메모리에 다시 접근하여 데이터를 가져오는 방식으로 사용된다.
세그멘테이션
세그멘테이션은 페이징과 유사하지만 다른 기법이다. 세그멘테이션 또한 프로세스를 여러개의 조각으로 쪼개는 것은 똑같다. 하지만, 단순히 동일한 크기로 쪼개는 것이 아니라 논리적 특성을 기준으로 프로세스를 쪼개게 된다. 예를 들어, 우리가 잘 아는 code, data, heap, stack 또한 일종의 세그멘테이션 기법으로 쪼개진 것이다. 데이터들의 용도나 목적을 기준으로 프로세스를 4개의 조각으로 쪼갠 것이다. 이 외에도 지역변수, 전역변수, 함수, 심볼 등을 기준으로 쪼개기도 한다고 한다. 페이징 기법은 페이지와 프레임의 크기가 동일하기 때문에, 페이지를 그대로 메인 메모리의 프레임에 적재하면 됐지만 세그멘테이션의 경우엔 각 세그먼트의 크기가 고정되어 있지 않기 때문에 메인 메모리를 미리 쪼개놓는 것이 불가능하다. 이러한 이유 때문에 세그멘테이션 기법은 그때 그때 각 세그먼트의 크기만큼 메모리 공간을 할당하게 된다. 세그멘테이션 또한 페이징 테이블처럼 세그먼트 테이블이 존재한다. 하지만, 조각의 수가 적은만큼 차지하는 용량이 매우 작아서 메인 메모리가 아닌 CPU의 레지스터에 저장된다고 한다. 이로 인해, 주소를 찾을 때 메인 메모리에 단 1번만 접근해도 된다. 세그먼트 테이블은 base와 Limit을 저장한다. A라는 세그먼트가 크기가 1400이라고 해보자. A를 메인 메모리의 1000번지로부터 1400 크기만큼 할당하였다면, base는 1000이 되고 Limit은 1400이 된다. 세그멘테이션이 언뜻 보면 페이징보다 좋아보이지만 실제론 페이징보다 많이 사용되지 않는다. 이유는 하나의 치명적인 문제점 때문이다.
세그멘테이션 기법은 외부 단편화를 야기한다.
세그멘테이션 기법은 위에서 말했듯이, 필요할 때마다 그 크기만큼 메인 메모리 상에 새로 할당하게 된다. 가변적인 크기로 메모리 상에서 할당과 해제를 반복하다 보면 자연스럽게 외부 단편화가 발생할 수 밖에 없다. 이로 인해 세그멘테이션 기법을 사용시에 메모리가 아주 비효율적으로 사용되는 상황이 잦아, 세그멘테이션 기법을 단독으로 사용하는 것은 선호되지 않는다고 한다.